Vadim Markovtsev, source{d}
Vadim Markovtsev, source{d}
Currently, we don't. Right now, we're focused on research, development and developer adoption
We want to be the machine learning pipeline on top of the world's source code, in both public and private repositories
In the future, we expect to make revenue by charging enterprises for deploying this pipeline on their code
Relax, we are very far from it
... won’t ask what problems can be solved with computers alone. Instead, ... ask: how can computers help humans solve hard problems? ... They won’t just get better at the kinds of things people already do; they’ll help us to do what was previously unimaginable.
Shared node roles for every language
We are going to deploypip3 install bblfshpython3 -m bblfsh -f /path/to/file
bblfsh/dashboard

Problem: given millions of repositories, map their files to languages
Names rule.
cat = models.Cat()cat.meow()
def quick_sort(arr):...
UpperCamelCase -> (upper, camel, case)camelCase -> (camel, case)FRAPScase -> (fraps, case)SQLThing -> (sql, thing)_Astra -> (astra)CAPS_CONST -> (caps, const)_something_SILLY_ -> (something, silly)blink182 -> (blink)FooBar100500Bingo -> (foo, bar, bingo)Man45var -> (man, var)method_name -> (method, name)Method_Name -> (method, name)101dalms -> (dalms)101_dalms -> (dalms)101_DalmsBug -> (dalms, bug)101_Dalms45Bug7 -> (dalms, bug)wdSize -> (size, wdsize)Glint -> (glint)foo_BAR -> (foo, bar)We apply Snowball stemmer to words longer than 6 chars
Let's interpret every repository as a weighted bag-of-words
We calculate TF-IDF to weigh the occurring identifiers
tensorflow/tensorflow:
tfreturn 67.78
oprequires 63.97
doblas 63.71
gputools 62.34
tfassign 61.55
opkernel 60.72
sycl 57.06
hlo 55.72
libxsmm 54.82
tfdisallow 53.67We can run topic modeling on these features
Run on the whole world -> funny tagging
Run per ecosystem -> useful exploratory search
Topic #36 "Movies" →
CTO Máximo Cuadros' profile →
Really good embedding engine which works on co-occurrence matrices
Like GloVe, but better - Paper on ArXiV
We forked the Tensorflow implementation
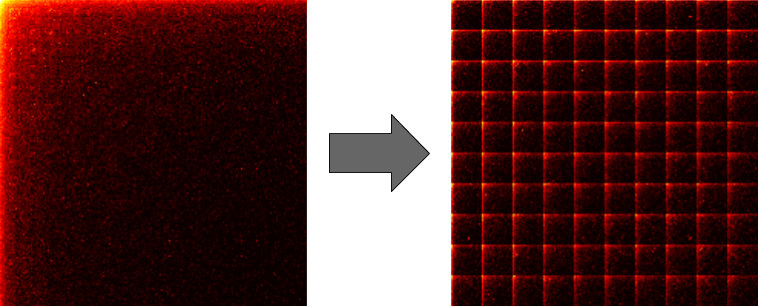
What if we combine bag-of-words model with embeddings?
We focus on finding related repositories
WMD evaluation is O(N3), becomes slow on N≈100
This allows to avoid 95% WMD evaluations on average
source{d}'s approach to WMD. GitHub
We tightened up the relaxed estimation
We used google/or-tools for the heavy-lifting
Result: WMD takes 0.1s on |bag| = 500 (pyemd takes 2s)
Babelfish currently supports only Python and Java, status
Models will be stored in Google Cloud Storage; not released yet, to use the deprecated ones:pip3 install vecinopython3 -m vecino https://github.com/pytorch/pytorch
python3 -m vecino --gcs test-ast2vec ...
Examples
If you wish to train the embeddings:
pip3 install ast2vecpython3 -m ast2vec repo2coocc -o tfcoocc.asdf \ https://github.com/tensorflow/tensorflowpython3 -m ast2vec preproc -o swivel_dataset -v 10000 \ -s 2500 --df df.asdfpython3 -m ast2vec train --input_base_path swivel_dataset ...python3 -m ast2vec postproc swivel_output id2vec.asdf
My contacts:
source{d} has a community slack!